استارتآپ Hugging Face و ServiceNow Research، بخش تحقیق و توسعه ServiceNow، StarCoder را منتشر کردهاند که جایگزینی رایگان برای سیستمهای هوش مصنوعی تولیدکننده کد در امتداد خطوط Copilot GitHub است.
سیستم های تولید کننده کد مانند DeepMind’s AlphaCode. CodeWhisperer آمازون؛ و OpenAI’s Codex، که به Copilot قدرت میدهد، نگاهی وسوسهانگیز به آنچه با هوش مصنوعی در قلمرو برنامهنویسی رایانه ممکن است ارائه میکند. با فرض اینکه روزی مسائل اخلاقی، فنی و قانونی برطرف شود (و ابزارهای کدنویسی مبتنی بر هوش مصنوعی بیشتر از آنچه حل میکنند باعث ایجاد باگها و سوء استفادههای امنیتی نمیشوند)، میتوانند هزینههای توسعه را به میزان قابل توجهی کاهش دهند و در عین حال به کدنویسها اجازه میدهند روی کارهای خلاقانهتر تمرکز کنند.
طبق مطالعهای از دانشگاه کمبریج، حداقل نیمی از تلاشهای توسعهدهندگان صرف اشکالزدایی میشود و نه برنامهنویسی فعال، که حدود 312 میلیارد دلار در سال برای صنعت نرمافزار هزینه دارد. اما تاکنون، تنها تعداد انگشت شماری از سیستمهای هوش مصنوعی تولیدکننده کد بهطور رایگان در دسترس عموم قرار گرفتهاند – که منعکسکننده انگیزههای تجاری سازمانهایی است که آنها را میسازند (نگاه کنید به: Replit).
StarCoder، که در مقابل مجوز استفاده بدون حق امتیاز را برای هر کسی، از جمله شرکتها، میدهد، بر روی بیش از 80 زبان برنامهنویسی و همچنین متنی از مخازن GitHub، از جمله اسناد و نوتبوکهای برنامهنویسی آموزش دیده است. StarCoder با ویرایشگر کد کد ویژوال استودیو مایکروسافت ادغام میشود و مانند ChatGPT OpenAI، میتواند دستورالعملهای اولیه را دنبال کند (مثلاً «ایجاد رابط کاربری برنامه») و به سؤالات مربوط به کد پاسخ دهد.
Leandro von Werra، مهندس یادگیری ماشین در Hugging Face و یکی از رهبران StarCoder، ادعا میکند که StarCoder با مدل هوش مصنوعی OpenAI که برای تقویت نسخههای اولیه Copilot استفاده میشد، مطابقت دارد یا بهتر عمل میکند.
فون ورا در یک مصاحبه ایمیلی به TechCrunch گفت: «چیزی که از نسخههایی مانند Stable Diffusion در سال گذشته آموختیم، خلاقیت و توانایی جامعه منبع باز است. «در عرض چند هفته پس از انتشار، جامعه دهها نوع از مدل و همچنین برنامههای کاربردی سفارشی ساخته بود. انتشار یک مدل قدرتمند تولید کد به هر کسی این امکان را میدهد که آن را با موارد استفاده خود تنظیم و تطبیق دهد و برنامههای پاییندستی بیشماری را فعال میکند.
ساخت مدل
StarCoder بخشی از پروژه BigCode بیش از 600 نفر Hugging Face و ServiceNow است که در اواخر سال گذشته راه اندازی شد و هدف آن توسعه سیستم های هوش مصنوعی پیشرفته برای کد به روشی “باز و مسئولانه” است. ServiceNow یک خوشه محاسباتی داخلی از 512 پردازنده گرافیکی Nvidia V100 را برای آموزش مدل StarCoder ارائه کرد.
گروههای کاری مختلف BigCode بر موضوعات فرعی مانند جمعآوری مجموعه دادهها، پیادهسازی روشهایی برای آموزش مدلهای کد، توسعه مجموعه ارزیابی و بحث در مورد بهترین شیوههای اخلاقی تمرکز میکنند. به عنوان مثال، گروه کاری حقوقی، اخلاقی و حاکمیتی سؤالاتی را در مورد مجوز داده، انتساب کد تولید شده به کد اصلی، ویرایش اطلاعات شناسایی شخصی (PII) و خطرات خروجی کد مخرب بررسی کرد.
BigCode با الهام از تلاشهای قبلی Hugging Face برای سیستمهای تولید متن پیچیده منبع باز، به دنبال رسیدگی به برخی از اختلافات ناشی از تولید کد مبتنی بر هوش مصنوعی است. سازمان غیرانتفاعی Software Freedom Conservancy از جمله GitHub و OpenAI را به دلیل استفاده از کد منبع عمومی، که همه آنها تحت مجوز مجاز نیستند، برای آموزش و کسب درآمد Codex مورد انتقاد قرار داده است. Codex از طریق APIهای پولی OpenAI و Microsoft در دسترس است، در حالی که GitHub اخیراً هزینه دسترسی به Copilot را شروع کرده است.
در بخشهای خود، GitHub و OpenAI ادعا میکنند که Codex و Copilot – که حداقل در ایالات متحده توسط دکترین استفاده منصفانه محافظت میشوند – با هیچیک از قراردادهای مجوز تخطی نمیکنند.
فون ورا گفت: «انتشار یک سیستم تولید کد توانا میتواند به عنوان یک پلتفرم تحقیقاتی برای مؤسساتی که به این موضوع علاقهمند هستند اما منابع یا دانش لازم برای آموزش چنین مدلهایی را ندارند، عمل کند. ما معتقدیم که در درازمدت این منجر به تحقیقات مثمر ثمر در مورد ایمنی، قابلیتها و محدودیتهای سیستمهای تولید کد میشود.»
برخلاف Copilot، StarCoder با 15 میلیارد پارامتر در طول چند روز بر روی یک مجموعه داده منبع باز به نام The Stack آموزش داده شد که دارای بیش از 19 میلیون مخزن نظارت شده و دارای مجوز مجاز و بیش از شش ترابایت کد در بیش از 350 زبان برنامه نویسی است. در یادگیری ماشینی، پارامترها بخشهایی از یک سیستم هوش مصنوعی هستند که از دادههای آموزشی تاریخی آموخته میشوند و اساساً مهارت سیستم را در یک مشکل، مانند تولید کد، تعریف میکنند.
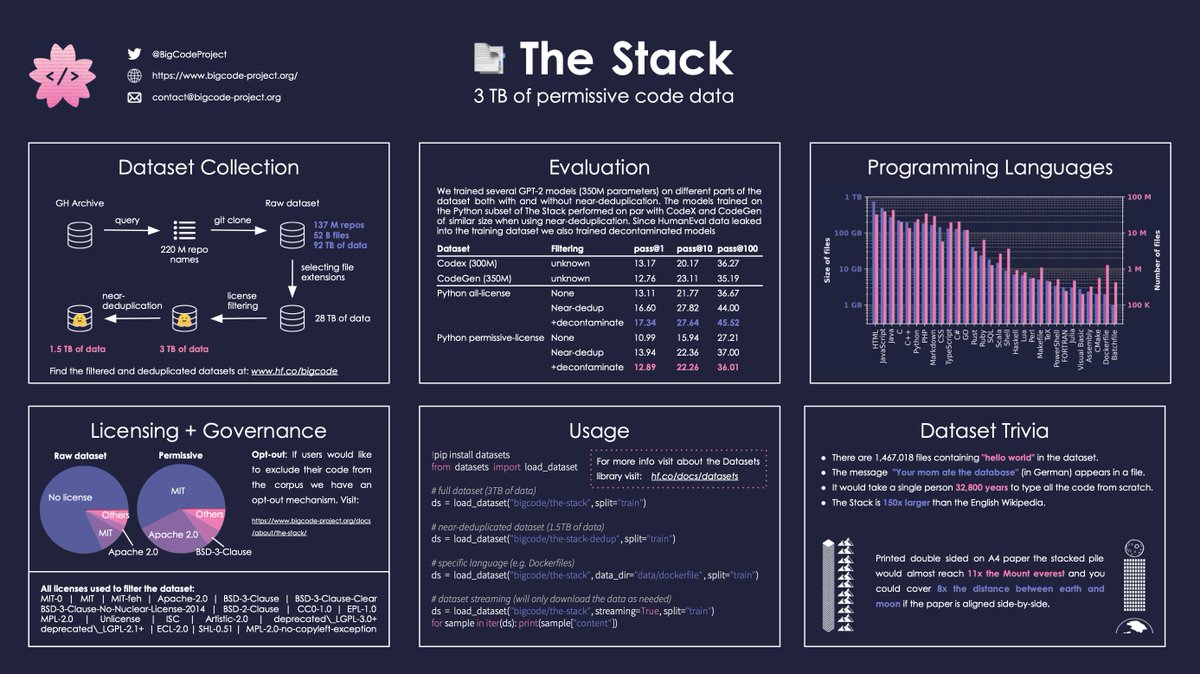
گرافیکی که محتویات مجموعه داده پشته را تجزیه می کند. اعتبار تصویر: BigCode
از آنجایی که به صورت مجاز مجوز دارد، کد از The Stack می تواند کپی، اصلاح و توزیع مجدد شود. اما پروژه BigCode همچنین راهی را برای توسعهدهندگان فراهم میکند تا از The Stack «انصراف دهند»، مشابه تلاشهایی که در جاهای دیگر به هنرمندان اجازه میدهند آثار خود را از مجموعه دادههای آموزش متن به تصویر هوش مصنوعی حذف کنند.
تیم BigCode همچنین برای حذف PII از The Stack، مانند نامها، نامهای کاربری، آدرسهای ایمیل و IP، و کلیدها و رمزهای عبور کار کرد. آنها یک مجموعه داده جداگانه از 12000 فایل حاوی PII ایجاد کردند که قصد دارند از طریق “دسترسی دروازه ای” برای محققان منتشر کنند.
فراتر از این، تیم BigCode از ابزار تشخیص کد مخرب Hugging Face برای حذف فایلهایی از The Stack استفاده کرد که ممکن است «ناامن» در نظر گرفته شوند، مانند مواردی که دارای اکسپلویتهای شناخته شده هستند.
مسائل مربوط به حریم خصوصی و امنیت سیستمهای هوش مصنوعی مولد، که در بیشتر موارد بر روی دادههای نسبتاً فیلتر نشده از وب آموزش داده شدهاند، به خوبی تثبیت شدهاند. ChatGPT یک بار داوطلبانه شماره تلفن یک روزنامه نگار را اعلام کرد. و GitHub اذعان کرده است که Copilot ممکن است کلیدها، اعتبارنامهها و رمزهای عبور را که در دادههای آموزشی خود در رشتههای جدید مشاهده میشود، تولید کند.
فون ورا گفت: “کد برخی از حساس ترین مالکیت معنوی را برای اکثر شرکت ها ایجاد می کند.” “به ویژه، به اشتراک گذاری آن در خارج از زیرساخت آنها چالش های بزرگی ایجاد می کند.”
به نظر او، برخی از کارشناسان حقوقی استدلال کردهاند که سیستمهای هوش مصنوعی تولیدکننده کد میتوانند شرکتها را در معرض خطر قرار دهند، اگر بخواهند ناخواسته متن دارای حق چاپ یا حساس از ابزارها را در نرمافزار تولید خود بگنجانند. همانطور که Elaine Atwell در مقاله ای در وبلاگ شرکت Kolide اشاره می کند، از آنجا که سیستم هایی مانند Copilot کد مجوزهای آن را حذف می کنند، تشخیص اینکه کدام کد مجاز است و کدام کد ممکن است شرایط استفاده ناسازگاری داشته باشد دشوار است.
در پاسخ به انتقادات، GitHub یک جابجایی اضافه کرد که به مشتریان اجازه میدهد از نمایش کد پیشنهادی مطابق با محتوای عمومی و بالقوه دارای حق نسخهبرداری GitHub جلوگیری کنند. آمازون به تبعیت از آن، CodeWhisperer مجوزهای مرتبط با توابع را که شباهت به قطعههایی که در دادههای آموزشی آن یافت میشود، به صورت اختیاری فیلتر میکند.
رانندگان تجاری
پس ServiceNow، شرکتی که بیشتر در زمینه نرمافزار اتوماسیون سازمانی فعالیت میکند، از این موضوع چه نتیجهای میگیرد؟ Harm de Vries، سرپرست آزمایشگاه مدل زبان بزرگ در ServiceNow Research و یکی از رهبران پروژه BigCode، گفت: «مدلی با عملکرد قوی و یک مجوز مدل هوش مصنوعی مسئول که استفاده تجاری را مجاز میکند».
یکی تصور می کند که ServiceNow در نهایت StarCoder را در محصولات تجاری خود بسازد. این شرکت فاش نمی کند که چه مقدار، به دلار، در پروژه BigCode سرمایه گذاری کرده است، به جز اینکه مقدار محاسبات اهدایی “قابل توجه” بوده است.
دی وریس گفت: «آزمایشگاه مدلهای زبان بزرگ در ServiceNow Research در حال ایجاد تخصص در توسعه مسئولانه مدلهای هوش مصنوعی مولد برای اطمینان از استقرار ایمن و اخلاقی این مدلهای قدرتمند برای مشتریان است. “رویکرد تحقیقات علمی باز BigCode به توسعه دهندگان و مشتریان ServiceNow شفافیت کامل را در مورد چگونگی توسعه همه چیز ارائه می دهد و نشان دهنده تعهد ServiceNow به مشارکت های اجتماعی مسئولانه به جامعه است.”
StarCoder به معنای دقیق متن باز نیست. در عوض، تحت یک طرح مجوز، OpenRAIL-M منتشر میشود که شامل محدودیتهای مورد استفاده «قانونی قابل اجرا» است که مشتقات مدل – و برنامههایی که از مدل استفاده میکنند – ملزم به رعایت آن هستند.
برای مثال، کاربران StarCoder باید توافق کنند که از مدل برای تولید یا توزیع کد مخرب استفاده نکنند. در حالی که نمونههای دنیای واقعی بسیار اندک هستند (حداقل در حال حاضر)، محققان نشان دادهاند که چگونه میتوان از هوش مصنوعی مانند StarCoder در بدافزارها برای فرار از اشکال اولیه تشخیص استفاده کرد.
اینکه آیا توسعهدهندگان واقعاً به شرایط مجوز احترام میگذارند، باید دید. به کنار تهدیدهای قانونی، هیچ چیزی در سطح فنی پایه وجود ندارد که مانع از نادیده گرفتن شرایط برای اهداف خود شود.
این همان چیزی است که در مورد Stable Diffusion فوق الذکر اتفاق افتاد، که مجوز مشابه محدود کننده آن توسط توسعه دهندگانی که از مدل مولد هوش مصنوعی برای ایجاد تصاویری از دیپ فیک افراد مشهور استفاده کردند نادیده گرفته شد.
اما این احتمال باعث دلسردی فون ورا نشده است، زیرا احساس میکند که جنبههای منفی منتشر نشدن StarCoder بر مزیتهای آن برتری ندارد.
او گفت: «در زمان راهاندازی، StarCoder به اندازه GitHub Copilot ویژگیها را عرضه نخواهد کرد، اما با ماهیت منبع باز آن، جامعه میتواند به بهبود آن در طول مسیر و همچنین ادغام مدلهای سفارشی کمک کند.
مخازن کد StarCoder، چارچوب آموزشی مدل، روشهای فیلتر کردن مجموعه دادهها، مجموعه ارزیابی کد و نوتبوکهای تحلیل تحقیق از این هفته در GitHub در دسترس هستند. پروژه BigCode آنها را در ادامه راه حفظ میکند، زیرا گروهها به دنبال توسعه مدلهای تولید کد توانمندتر هستند که توسط ورودیهای جامعه تقویت میشود.
مطمئناً جای کار وجود دارد. در مقاله فنی همراه با انتشار StarCoder، Hugging Face و ServiceNow میگویند که این مدل ممکن است محتوای نادرست، توهینآمیز و گمراهکننده و همچنین PII و کد مخرب تولید کند که توانسته از مرحله فیلتر کردن مجموعه داده عبور کند.